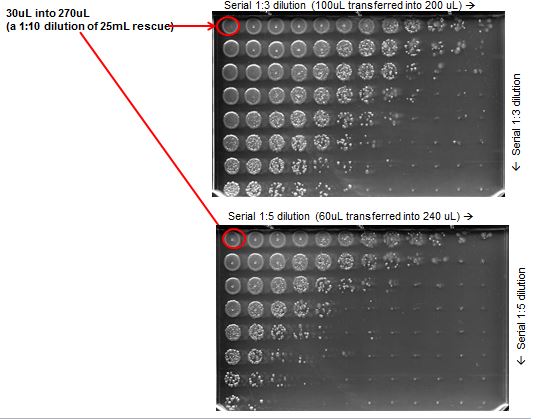
In a previous post I discussed using a 96 channel pipettor and Omniplates for titering bacterial cultures. Here I show how to automate the counting process. Start with a two dimension serial dilution of a culture as shown on the plate below:
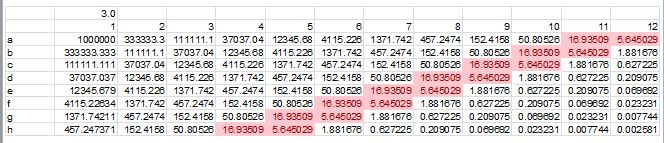
A 2D dilution simulation suggests that a small number of regions will be in the correct range for accurate titer determination (red cells):
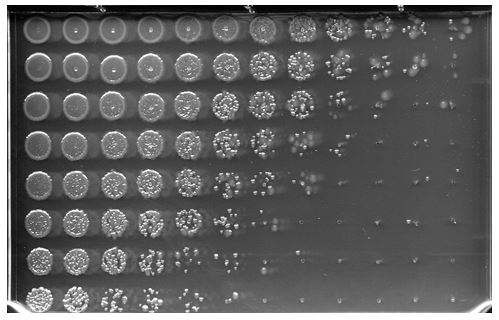
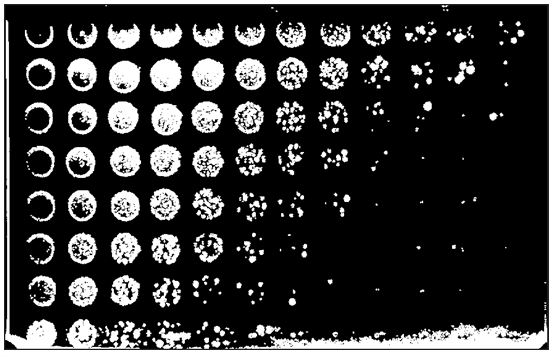
Then count. I will decompose the main image into 96 smaller images which can then each be processed individually. Identify the upper right corner origin and the segment.width, 103 pixels in this case. Print out the coordinates of individual segments
#convert a well number to row/column designation. getWell96 <- function( id ){ n <- 1:96 row <- rep(LETTERS[1:8],12) col <- sort(rep(1:12, 8)) name <- I(paste(row,col, sep="")) #I() is as.is to prevent factorization well.ids <- data.frame(name, n)
if( id %in% name) {well.ids[well.ids$name==id,"n"] }else{ well.ids[well.ids$n==id,"name"]} }
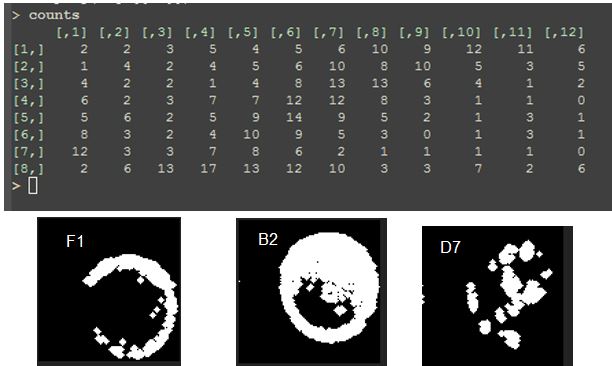
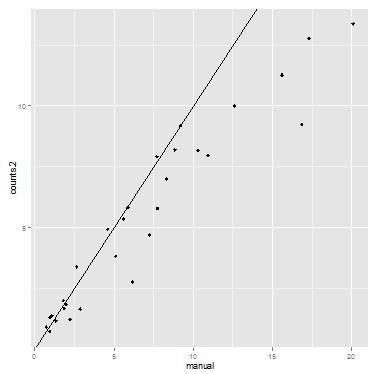
The diagonal with a majority of counts >10 would be predicted to give the most reliable results. Now compare algorithmic vs. manually determined counts:
1 2 3 4 5 6 7
names(d)[2:3] <- c("algorithm","manual") x <- d$algorithm y <- d$manual #we will make y the response variable and x the predictor #the response variable is usually on the y-axis plot(x,y,pch=19)
Make an attemp to fit a couple of polynomial lines - for predictive purposes.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
#fit first degree polynomial equation: fit <- lm(y~x) #second degree fit2 <- lm(y~poly(x,2,raw=TRUE)) fit3 <- lm(y~poly(x,3,raw=TRUE))